前言
上一章我们学习了梯度下降法,在那一章中提及了计算梯度所需使用的反向传播算法,这一章我们将进一步探讨什么是反向传播算法
反向传播算法(Backpropagation,简称 BP)是神经网络训练中最核心的算法之一。它通过计算损失函数对每个权重的梯度,指导网络参数的更新,从而使网络能够学习数据中的模式。
什么是反向传播?
在上一章我们提到了,梯度下降法的关键是求代价函数的负梯度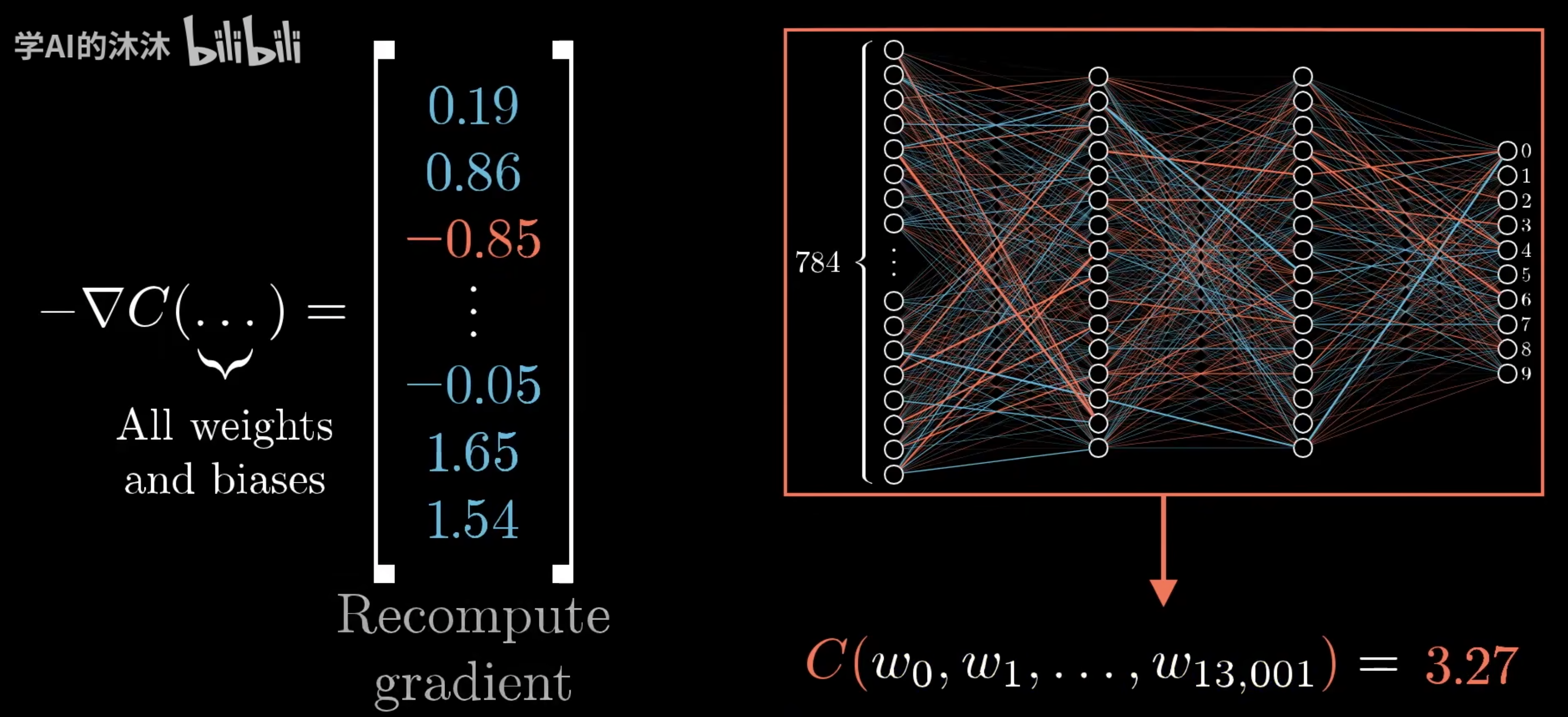
梯度向量的每一项大小表示代价函数对于每个参数的敏感程度,即参数调整对代价结果的影响有多大
首先我们只关注一个训练样本,来讲解反向传播的过程。假设我们现在的模型还没完全训练好,那么当识别执行到这张2的时候,所获取的输出层的激活值看起来很随机。因为我们最终想要获得是2,因此我们希望第三个的输出值变大,其他的数值变小
输出层的激活值,取决于上一层与输出层神经元之间的权重,偏置值和上一层神经元的激活值,通过修改这三个就可以调整输出层神经元的激活值。
当我们提到梯度下降时,我们并不只看每个参数是该增大还是减小,而是关注调整哪个参数的性价比最高。这涉及到“赫布理论”,简单的说就是一通激活的神经元关联在一起。
当我们把所有对于2的期待值和别的输出神经元的期待值全部加起来,作为对如何改变倒数第二层神经元的指示。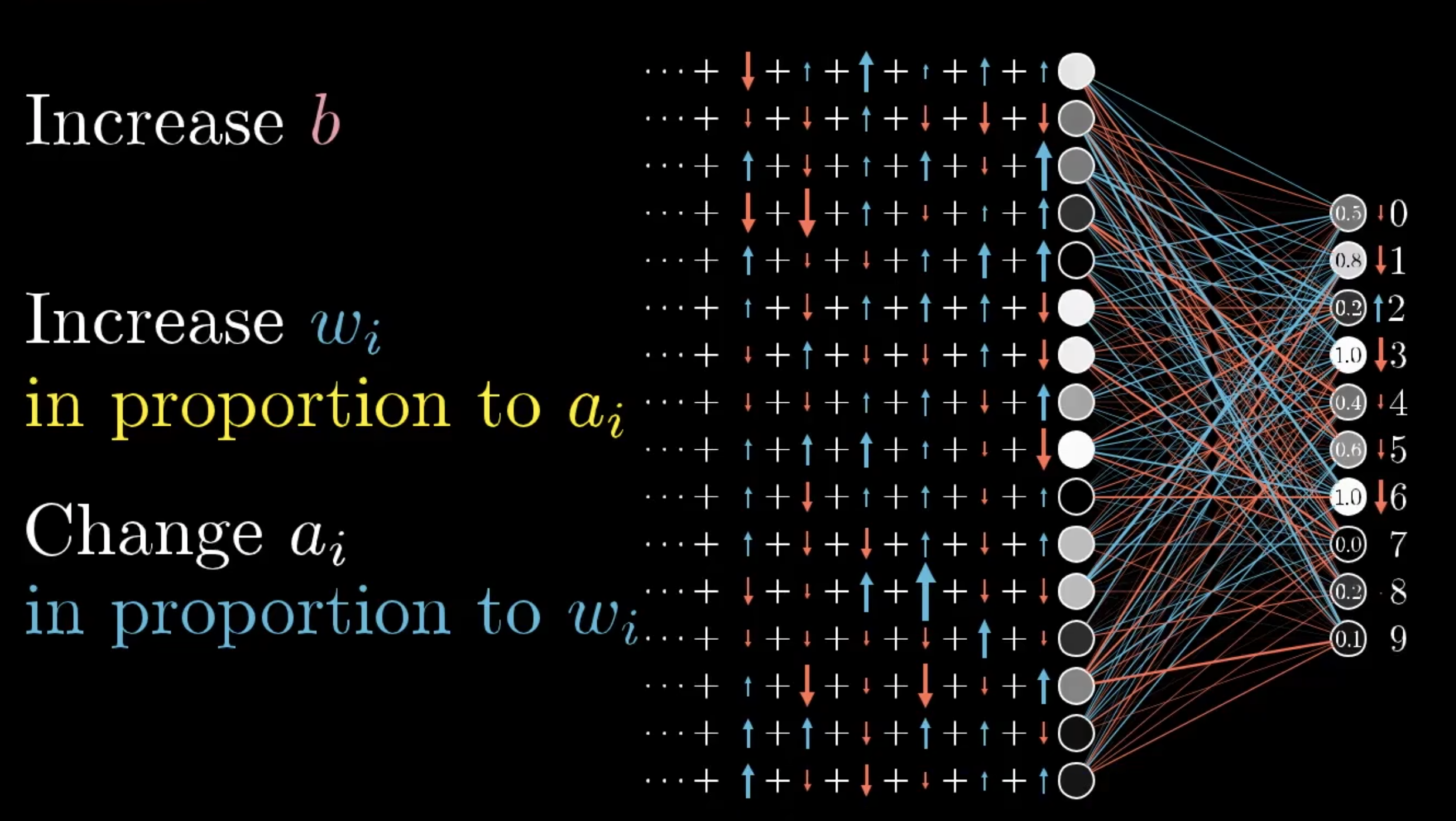
这些期待变化不仅是对应权重的倍数,也可以是每个神经元激活值改变两的倍数。这其实就是在实现“反向传播”的理念了。当我们把所有期待值加起来,就得到了一串对倒数第二层改动的变化量。有了这些,你就可以重复这个过程,改变影响倒数第二层神经元激活值的相关参数。从后一层到前一层,把这个过程一直循环到第一层。
不过目前我们讨论的知识单个训练样本,回到整个训练集,将整个训练集过一遍反向传播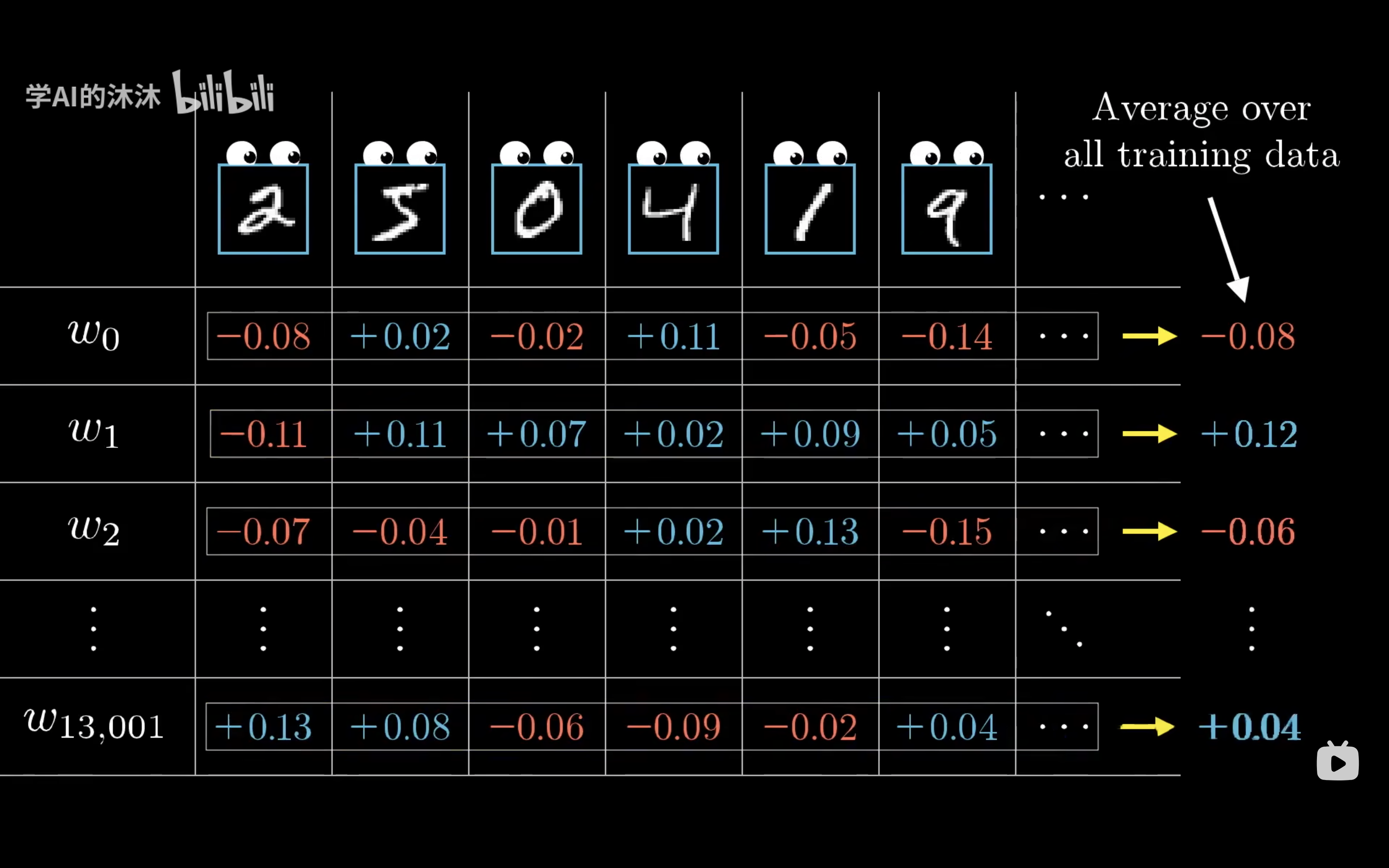
记录下每个样本想要怎么修改权重与偏置,最后取一个平均值。这一系列的权重偏置的平均微调大小。不严格来说就是上一章提到的代价函数的负梯度
不过实际操作中,如果每次梯度下降都需要用上所有的样本进行计算的话,整体耗时就太长了。因此实际上我们会将样本集打乱,然后分成很多小组。算出某个小组下降的一步,这也许不是整个训练集的梯度,但是这样够快,同样也能到达局部最低
具体公式
前面提到了反向传播的概念,那么这一部分,我们将进行公式的推导。首先为了简化推导过程,我们先简化神经网络,假设我们的网络每一层只有一个神经元
我们先关注最后两个神经元。我们给最后一个神经元的激活值一个上标L,表示它在L层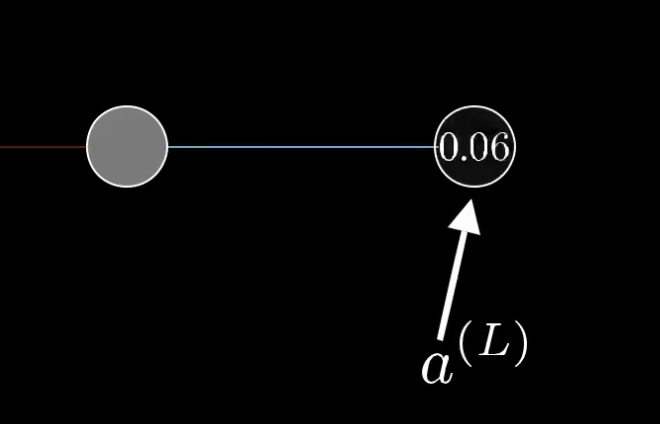
那么前一个神经元的激活值就是 $a^{(L-1)}$。我们把最终层激活值要接近的目标叫做y,那么y要么是0要么是1。那么这个简单网络对于单个训练样本的代价,就等于$(a^{(L)}-y)^2$,对于这个样本,我们把这个代价值标记为$C_0$。而最终层的激活值$z^{(L)}=w^{(L)}*a^{(L-1)}+b^{(L)}$计算获得,即权重乘以上一层神经元激活值加偏置。将这个值至于一个特定的非线性函数中,及$a^{(L)}=\sigma(z^{(L)})$
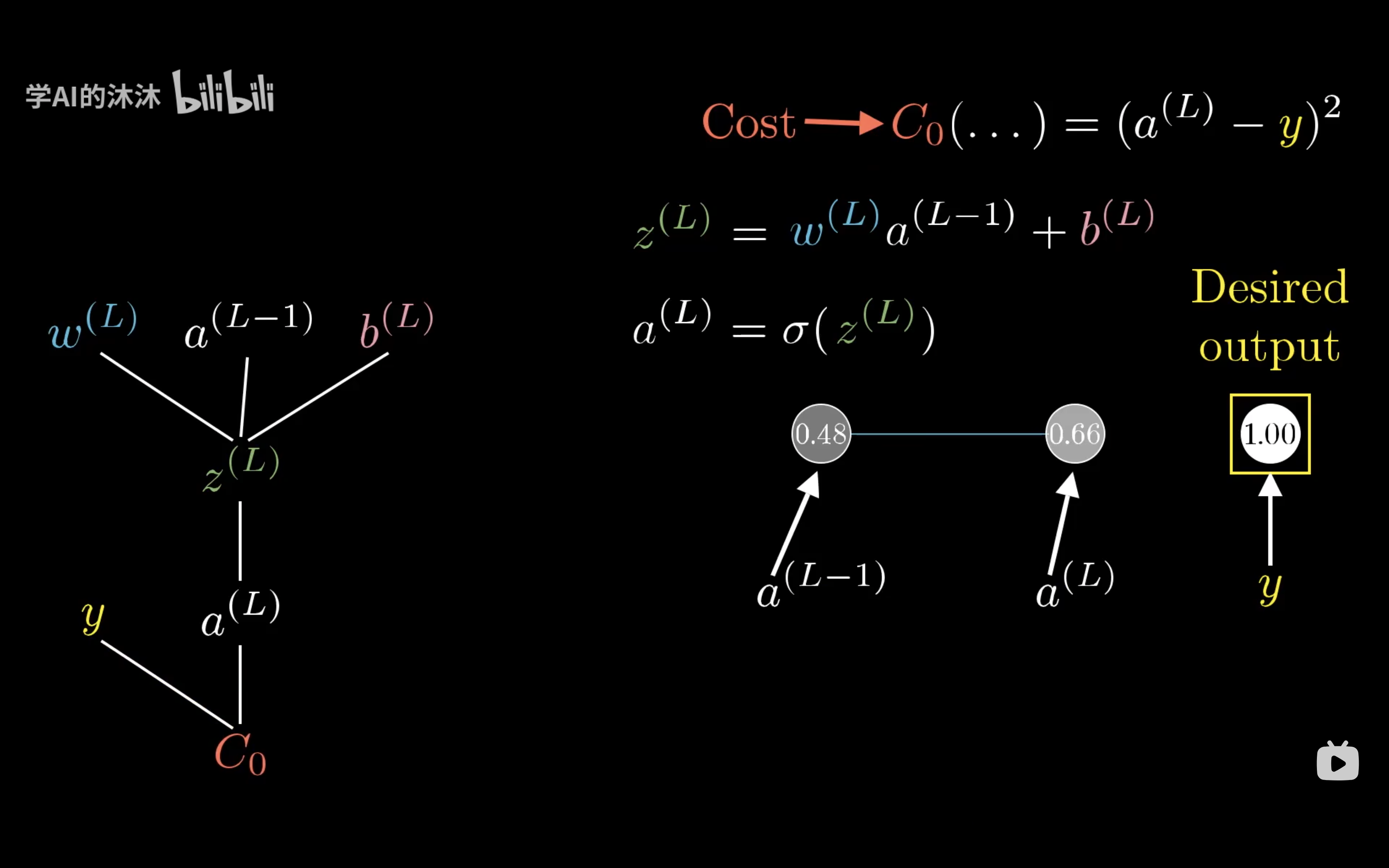
我们假设这些数字都对应一个数轴,我们第一个目标就是理解代价函数对权重$w^{(L)}$的微小变化有多敏感。或者换句话说,就是求C对$w^{(L)}$的偏微分
偏导数:
偏导数是多元函数求导的一种方式。
当你有一个包含多个变量的函数(比如 f(x, y) = x²y),你想知道当只改变其中一个变量、而保持其他变量不变时,函数如何变化,这时就用偏导数。
简单例子:
假设 f(x, y) = x²y
对 x 求偏导数(把 y 当作常数):∂f/∂x = 2xy
对 y 求偏导数(把 x 当作常数):∂f/∂y = x²
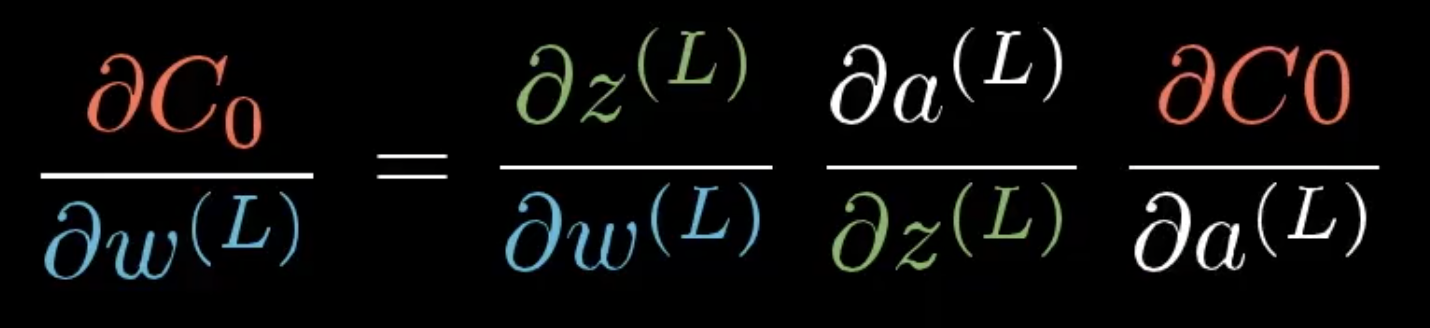
最终公式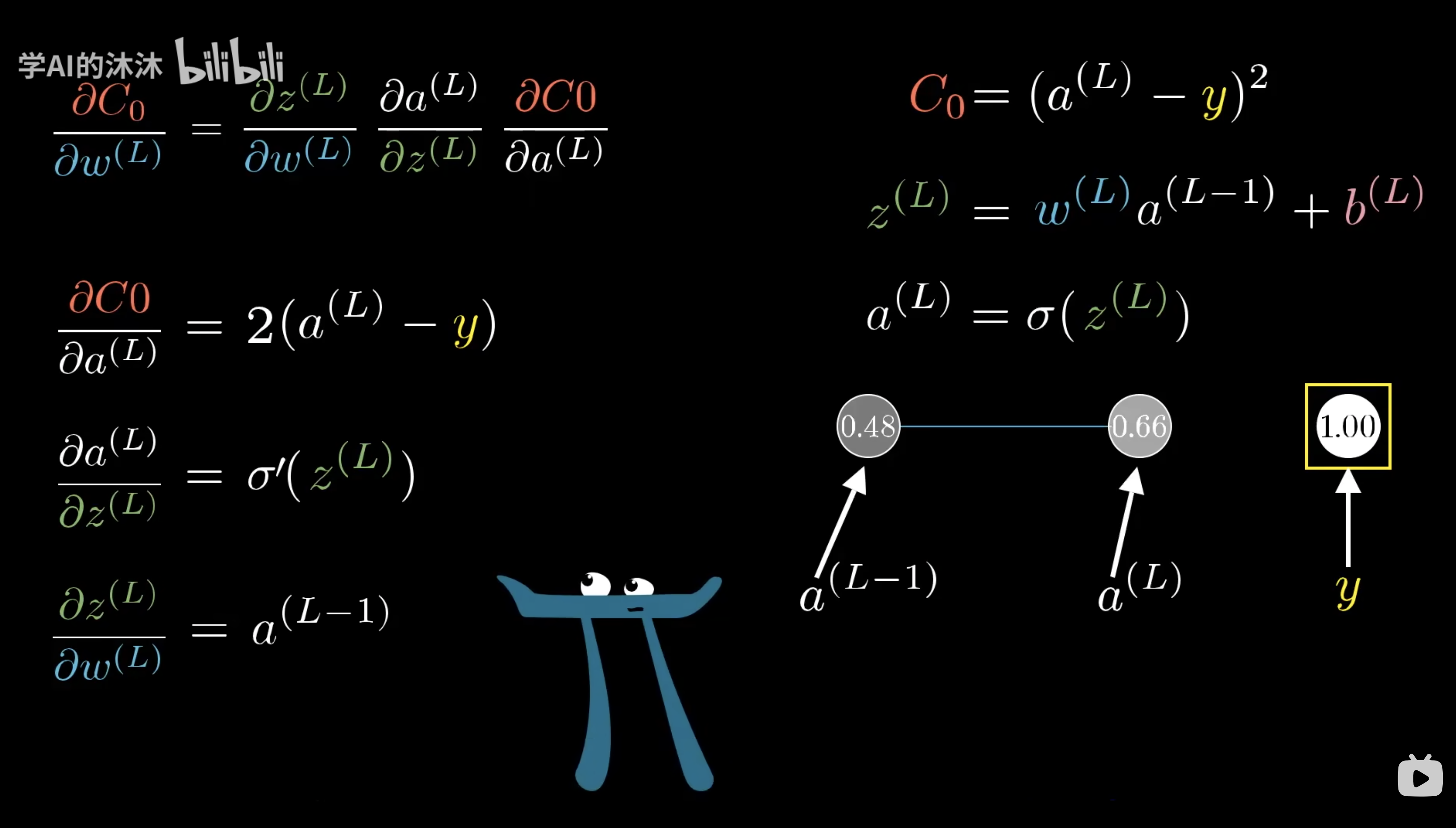
我们逐一求导
$C_0=(a^{(L)}-y)^{2}$的导数就是$2*(a^{(L)}-y)$
最终求导后相乘就是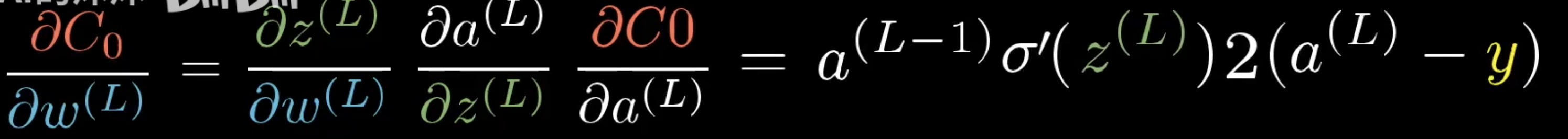
这个指示包含一个训练样本的大家对于$w^{(L)}$的导数。由于总的代价函数是许许多多训练样本所有代价的总平均。它对权重的导数就要求,这个表达式之于每个训练样本的平均
当然这只是梯度向量的一个分量。梯度向量整体则由代价函数对每个权重和每个偏置求偏导构成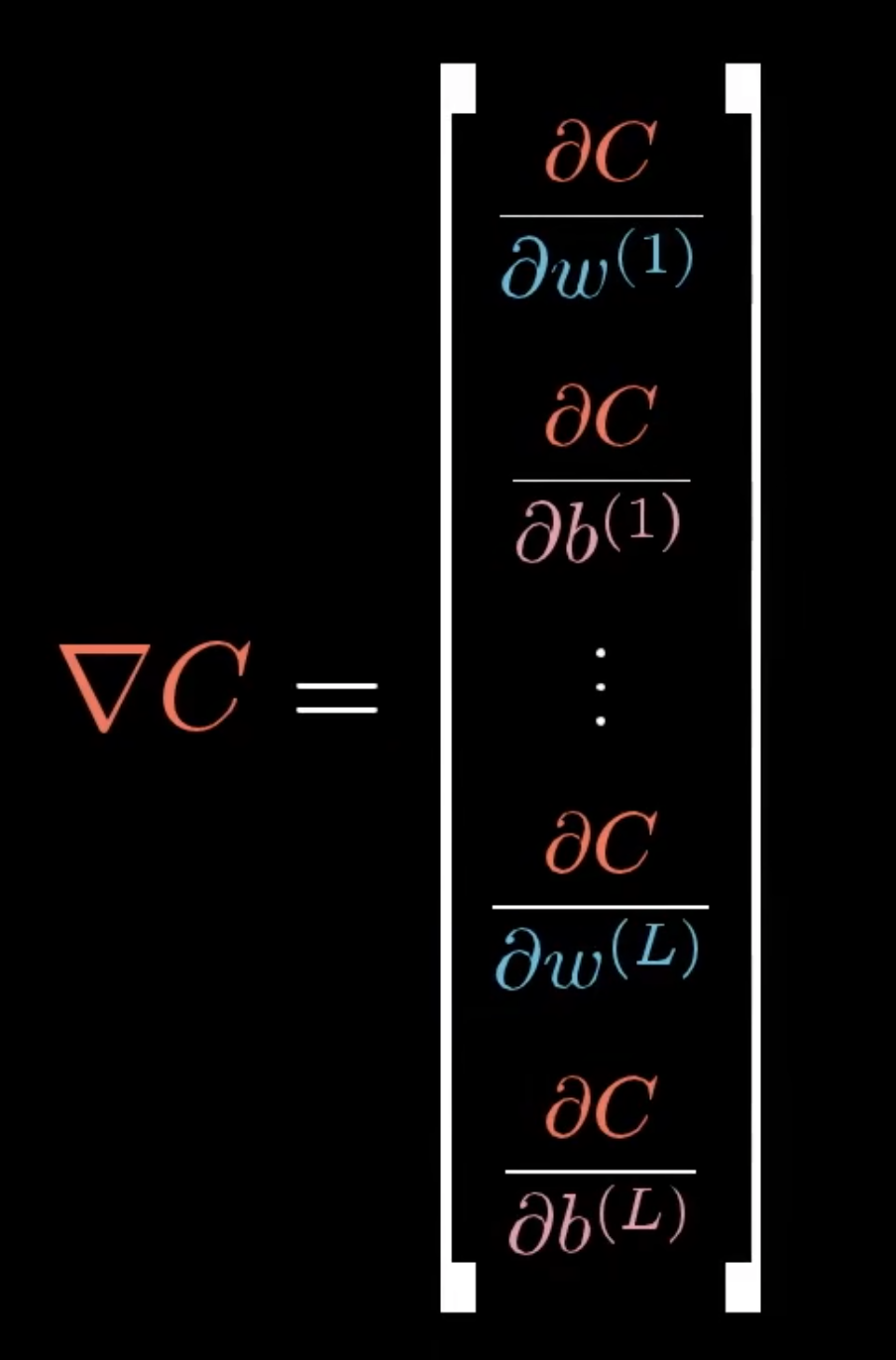
偏置值的求导步骤也基本相同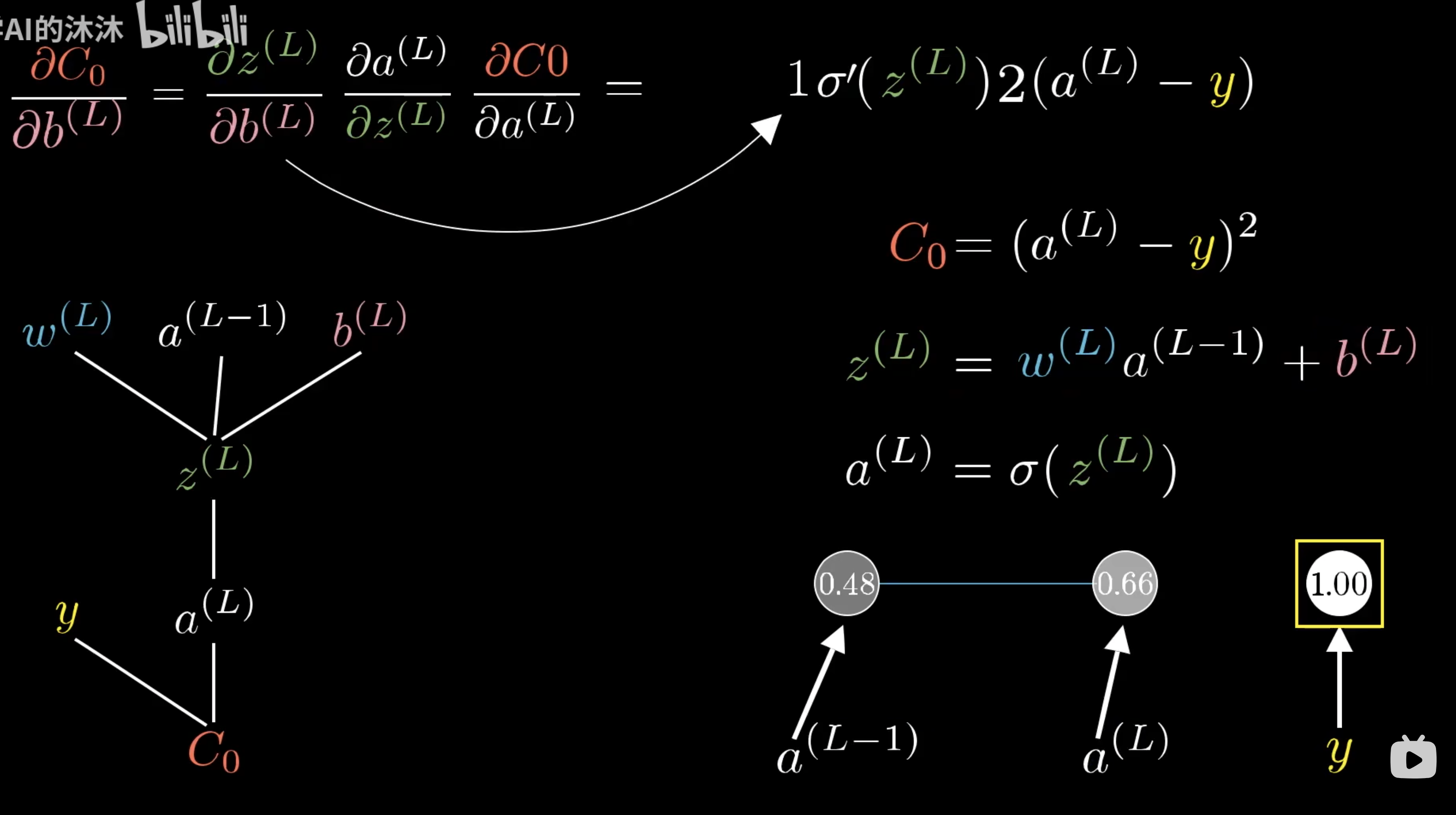
不过这个例子相对简单,每层只有一个神经元,不过即便变回我们的示例神经元,也不会复杂太多,只不过需要增加下标。
我们增加下标来表示神经元处在L层的第几个。我们用K表示L-1层的第K个,用J表示第L层的第K个。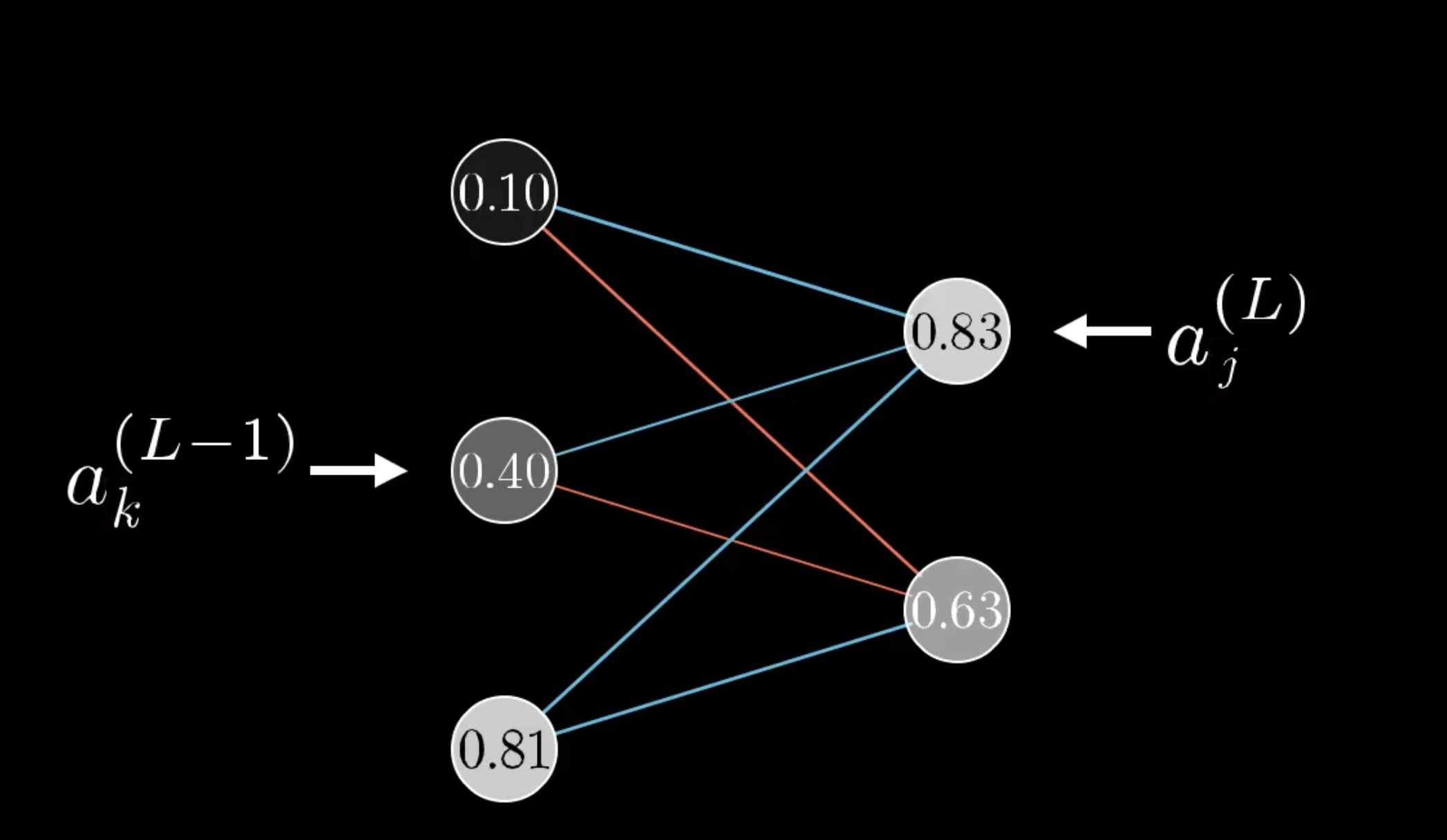
那么$Z^{(L)}$和$C_0$的变化如下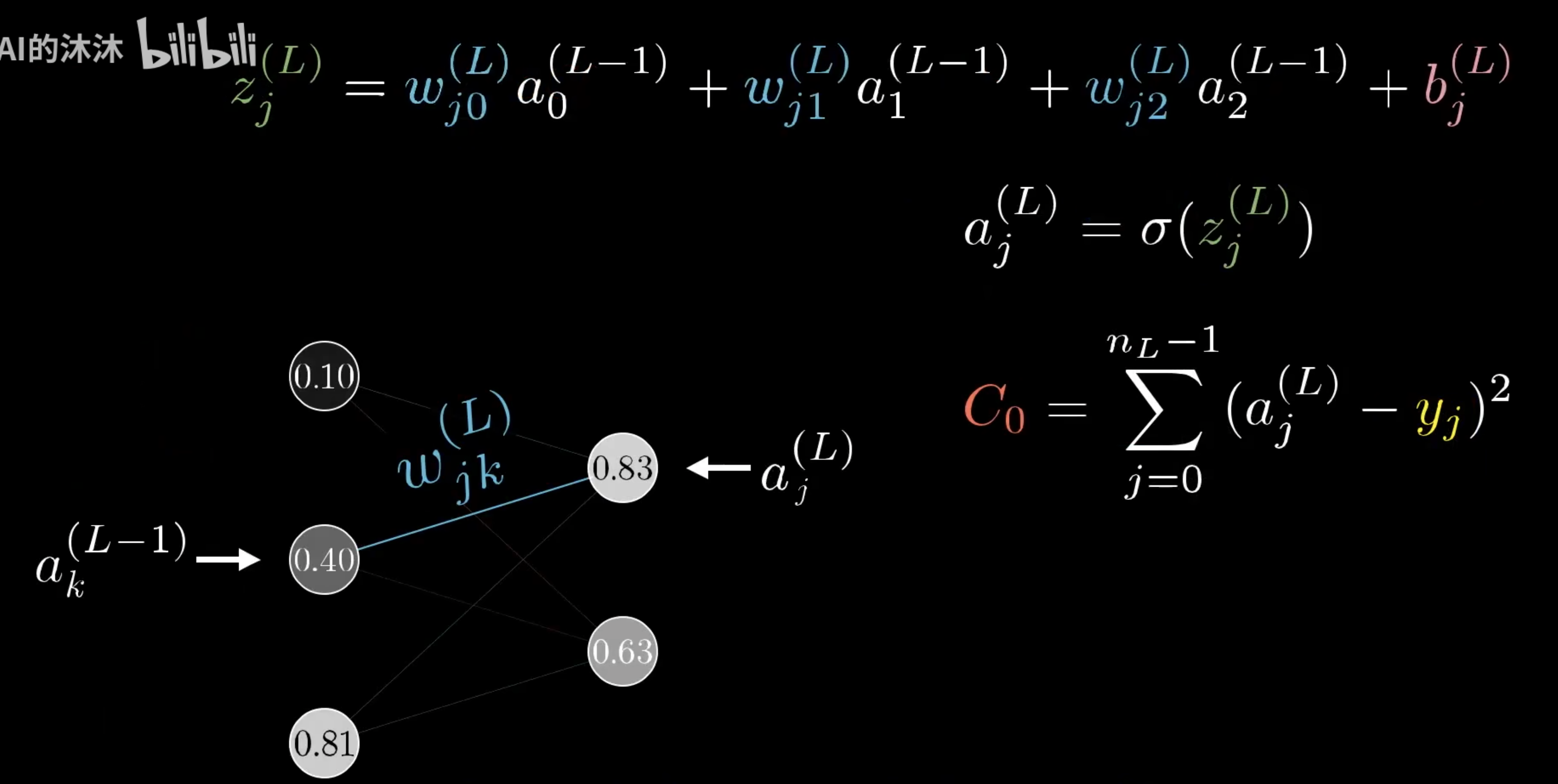
最终的对于权重偏微分如下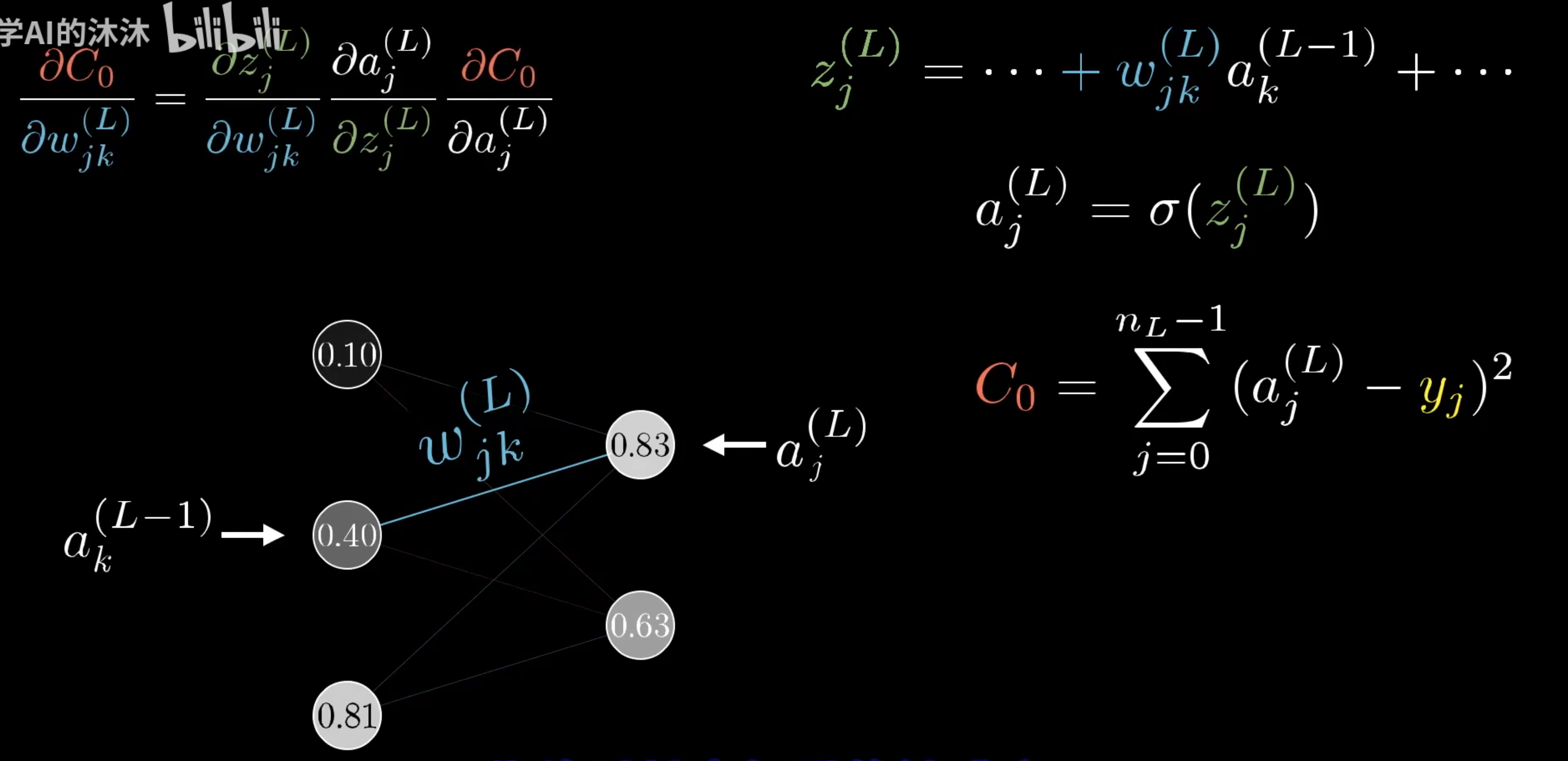
对于上一层激活值的偏微分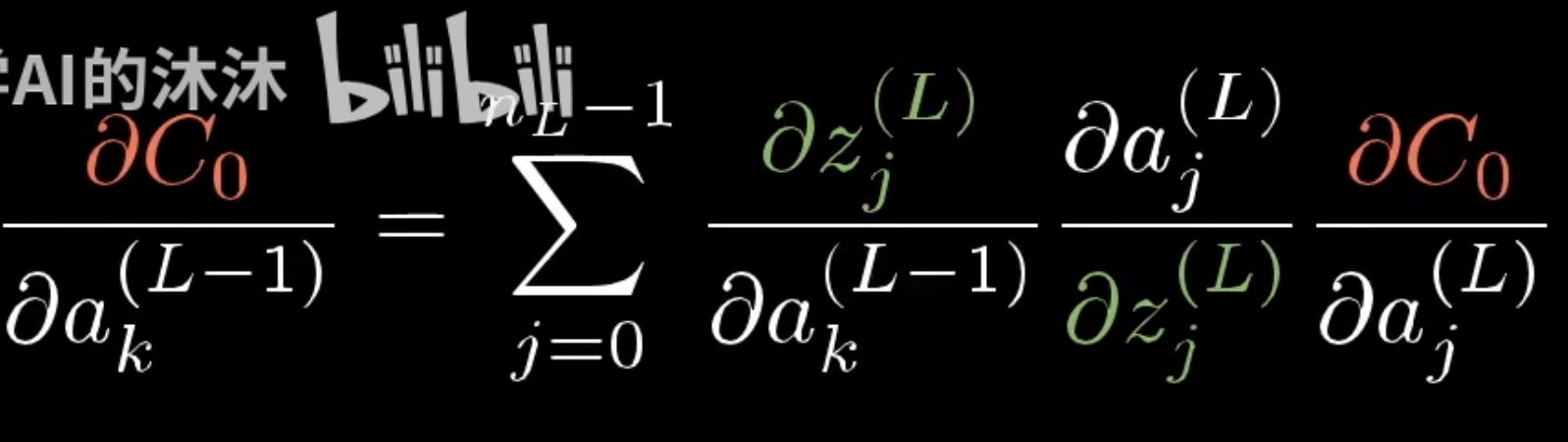
链式法则表达式给出了决定梯度每个分量的偏导
扩展阅读
以下是关于反向传播算法的优质学习资源,供进一步深入学习:
官方文档与经典教材
- Neural Networks and Deep Learning - Michael Nielsen - 反向传播算法的经典免费在线教材,讲解深入浅出
技术博客
- 反向传播算法详解 - 知乎 - 中文详细推导,适合加深理解
- Backpropagation Explained Visually - 可视化讲解反向传播
实践教程
- CS231n Convolutional Neural Networks for Visual Recognition - 斯坦福经典课程,反向传播专题
- PyTorch 官方教程 - Autograd - 自动微分实现原理
延伸阅读
- Understanding LSTM Networks - 理解反向传播在循环神经网络中的应用
- The Vanishing Gradient Problem - 梯度消失问题及解决方案