上一章学习了神经网络的结构,但也留下了一个问题,就是神经网络是如何学习的。这一章,我们将进一步讲解深度神经网络的学习基础——梯度下降算法
如何调整参数
上一章我们讲到,识别2828像素手写数字的神经网络整体可以整体看作一个函数,输入就是28 * 28个像素的灰度,也就是第一层神经元的激活值。而函数参数,就是13002个权重和偏置值。那么,如何获得这13002个参数的值,使神经网络对于图像识别的准确率达到最优,就是这章的重点。
之所以使用这个图像识别的神经元网络作为我们示例,是因为这个MNIST数据库收集了众多的手写数字图像,并标注了每个图像对应的数字作为训练集。现在我们具备了训练集,假设我们随机生成一组权重和偏置值,我们该如何定义这组参数对于神经网络识别图片能力的好坏呢,这里就引出了一个新的概念——代价函数(Cost Function)
对于一个正确的识别来说,作为最后一组结果层的神经元,应该其他数字的*激活值几乎为0,而对应那个数字的神经元它的激活值应该近似于1。但是由于我们是随机生成的参数,所以获得的最终结果可能每个结果层神经元的激活值都是一个小数。我们将实际结果的每个神经元的激活值减去预期的每个神经元的激活值,并计算他们的平方和,这就是训练集中单个训练样本的“代价”。
如果图像识别的越准确,则这个代价就越小,而如果识别的越错误,则代价越大。而将训练集中每个样本的代价相加求平均,这个平均代价(又称经验风险, Empirical Risk),就用来形容这组参数的好坏,我们要做的就是寻找平均代价最小的那组参数。
回到我们之前说过的,神经网络可以看成一个函数,代价的计算也可以看作一个函数,这个函数的输入是13002个权重和偏置值,输出是一个数值表示代价的平方和,而参数则是样本集里的所有样本。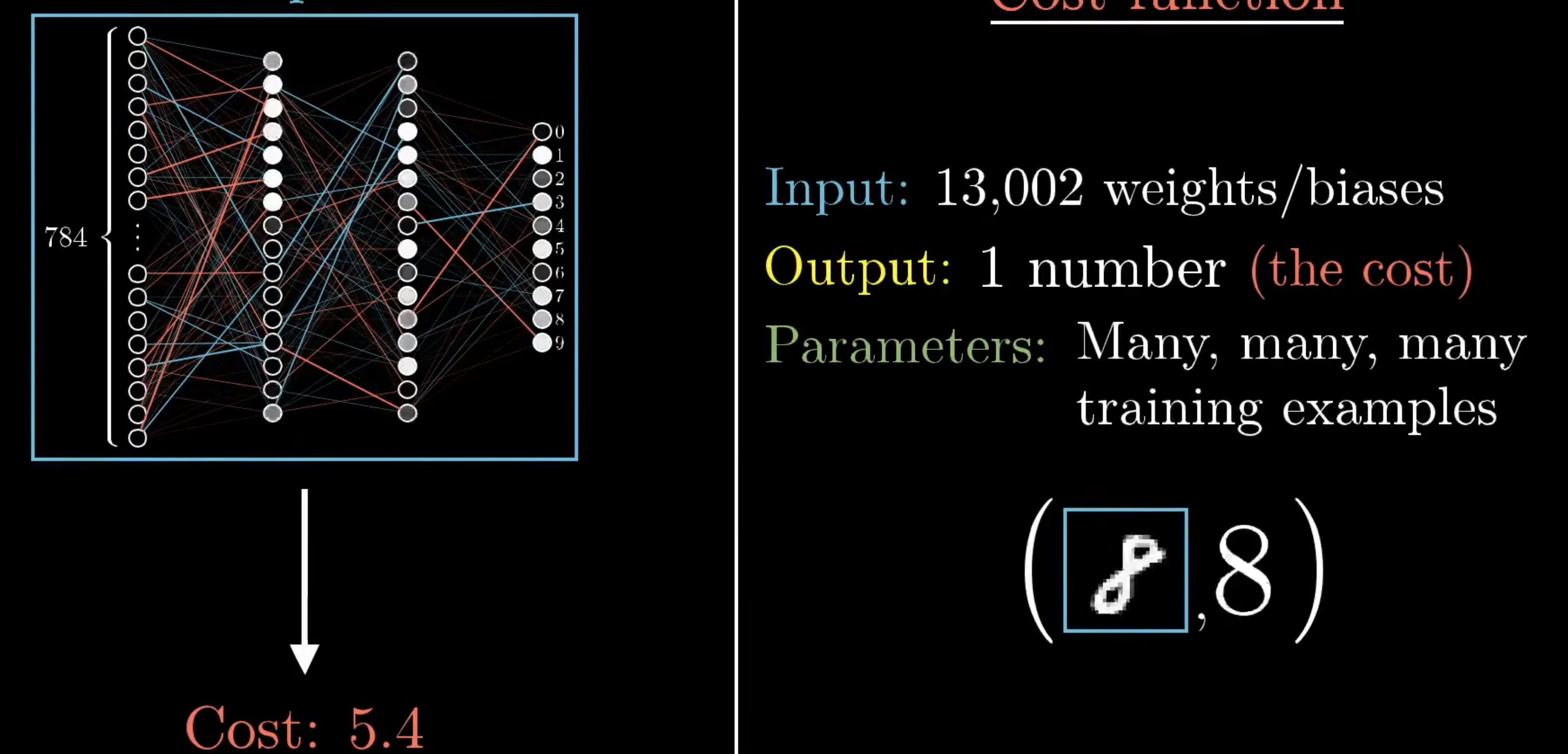
所以说,求最优权重值和偏置值,其实就是在求代价函数的最低点。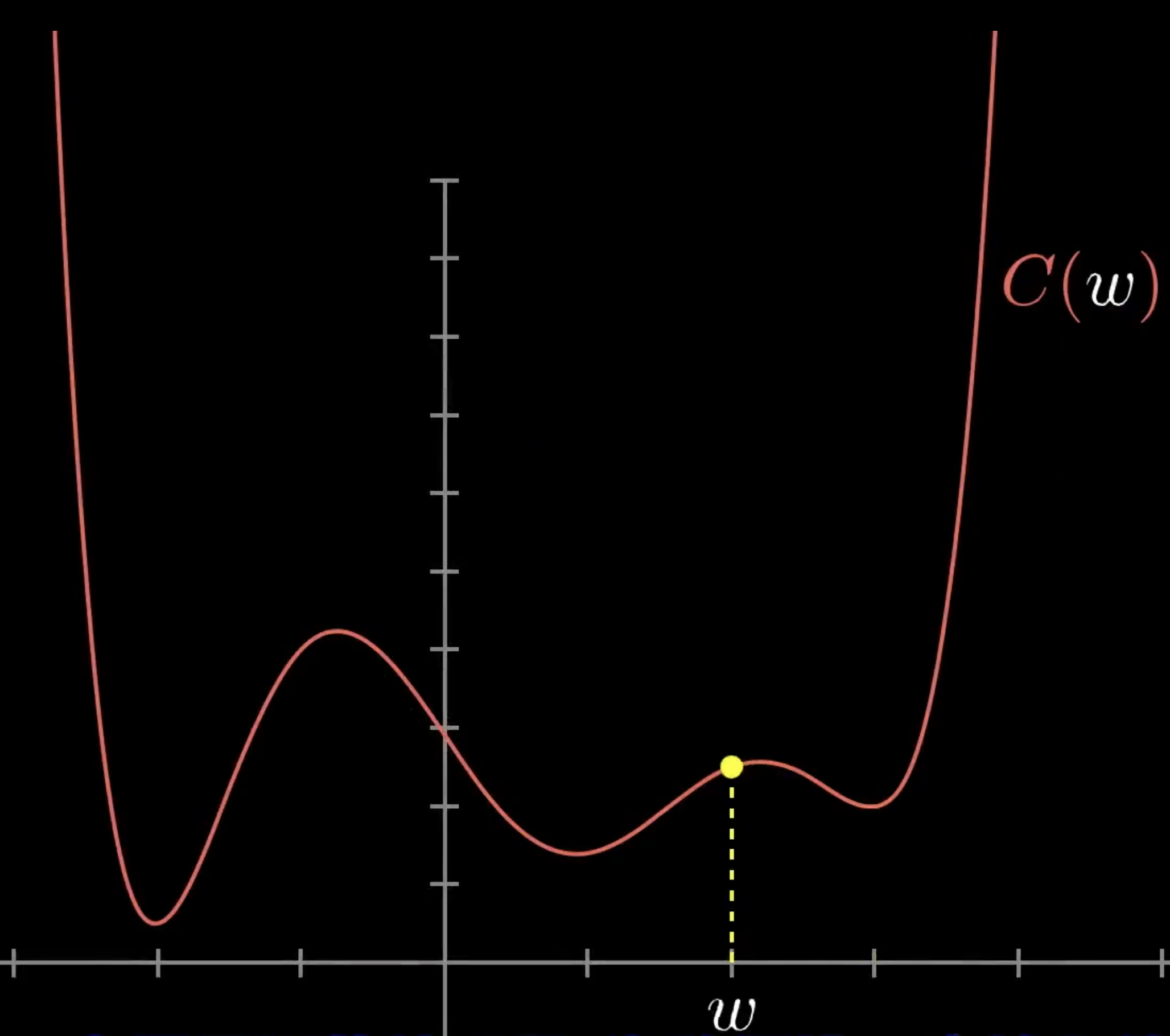
最低点
那么如何求一个函数的最低点呢,我们现在有13002个未知值。让我们先从最简单的一元函数开始。学过微积分的我们都知道,一些简单函数的最小值是可以直接计算出来的。但是对于复杂函数,尤其是我们这种拥有众多变量的参数,是很难计算的。一个更灵活的方法是,以一元函数为例,先去一个随机值,然后考虑这个值是增加还是减少(左移还是右移)函数值会变小。那么学过导数的我们都知道,可以求导获取这个函数在某点的斜率,斜率如果为正,则函数是递增的,需要左移,斜率如果为负,则函数是递减的,则需要右移。按照移动方向移动一定距离,再求该点的斜率,再移动,你就会逼近这个函数在某个区域的最小值。可以想象成一个小球,从函数曲线的不同位置释放,最后会落在函数曲线的某个坑中,这个坑就是局部最小值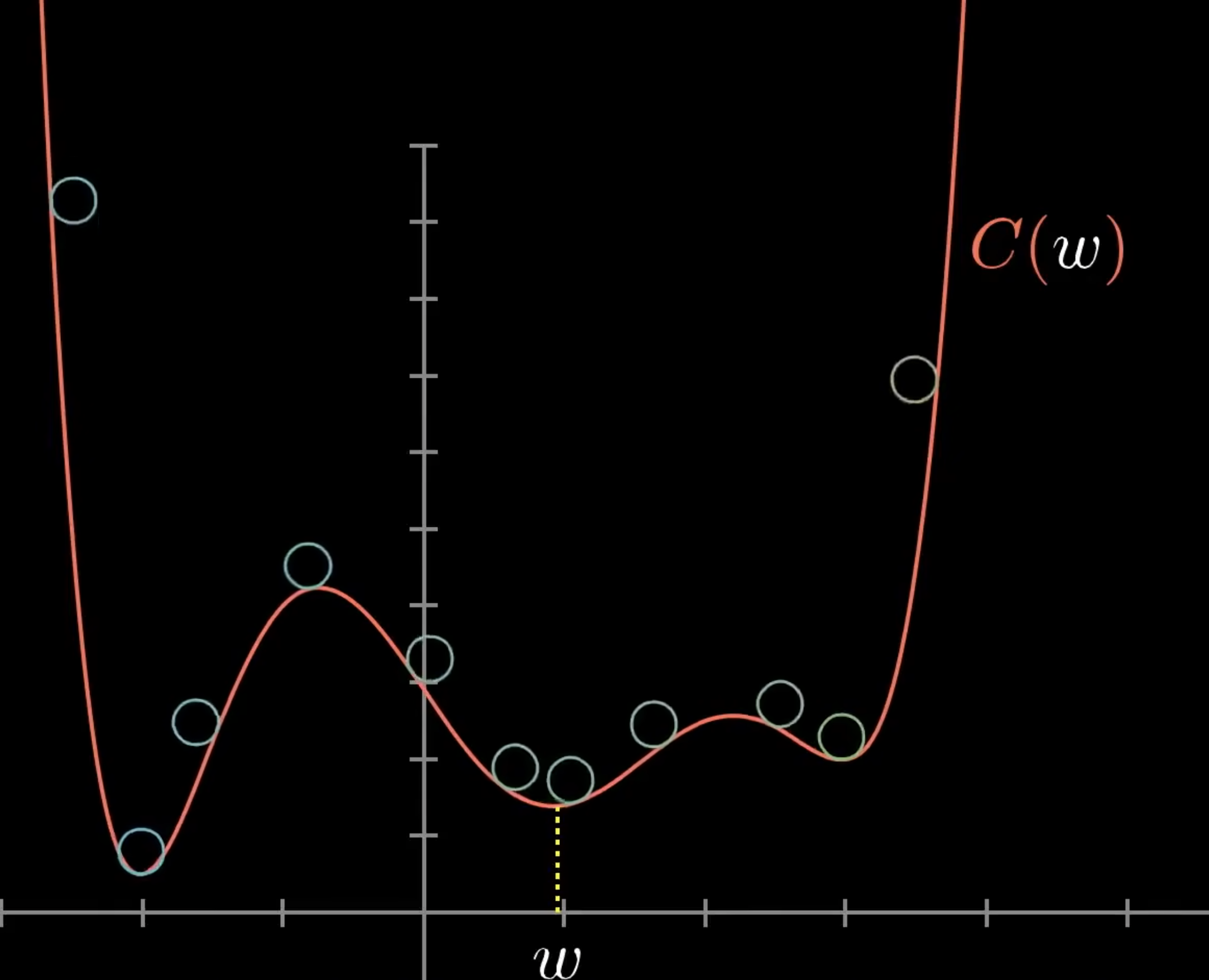
但是局部最小值不一定代表全局最小,神经网络也会遇到这个问题。另外,将移动的大小(也就是步长)跟斜率的绝对值大小成正比,即斜率绝对值越大,移动距离越长,越小移动距离也越小,可以有效的防止因为步长过长而调试过头。
我们进一步扩充为二元函数,那么就从线变成了面。斜率也就变成了向量,将整个图形类比成山,也就是往哪个方向走,上山最快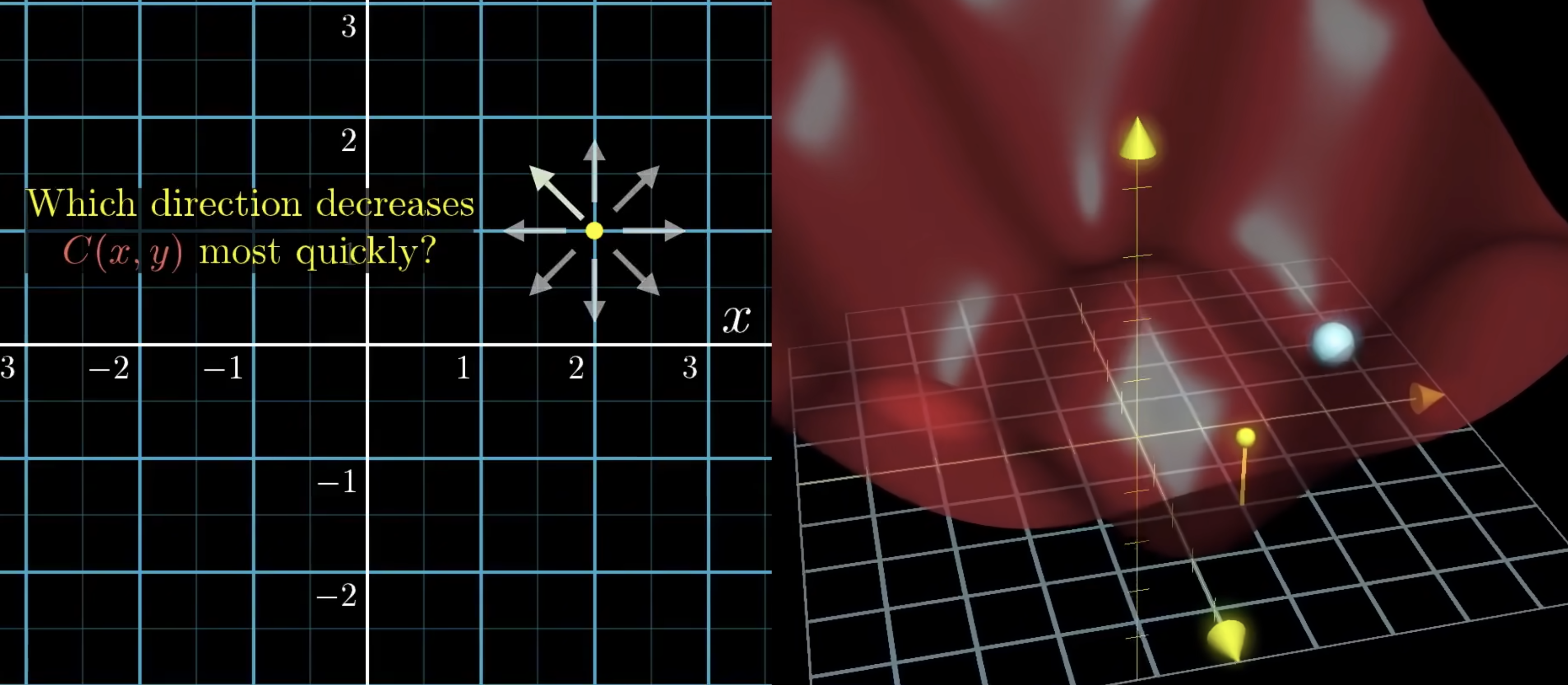
这里就要引入一个多元微积分的概念——梯度,一个函数的梯度(Gradient)是一个向量,表示函数在某一点处变化最快的方向和变化率
梯度的核心特性
- 方向:梯度指向函数值增长最快的方向
- 大小:梯度的模长表示该方向上的变化率
- 正交性:梯度与等值线(或等值面)垂直
所以按照梯度的反方向,也就是负梯度方向走,代价函数的值下降的最快。
那我们计算代价函数最小值的方法,就是先随机取一个点,计算这个点的梯度,然后按照反梯度方向下降一点,再计算梯度,依次循环,就能到达这个随机初始点的局部最低点,哪怕是我们13002元函数,也是如此。
假设我们把13002个权重偏置列成一个列向量,那么代价函数的负梯度,无非也是一个列向量。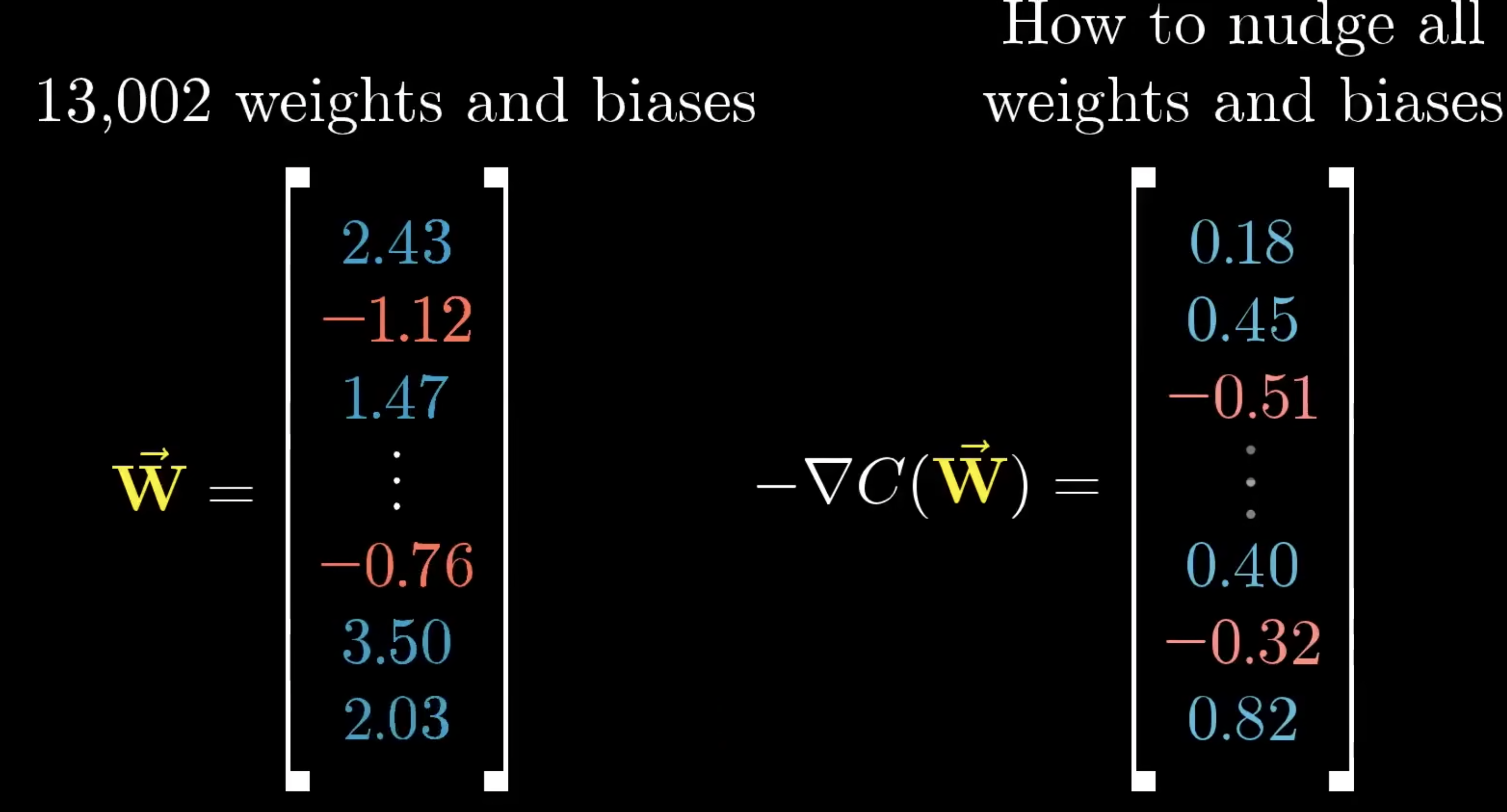
这个列向量的每一行都对应了某个权重偏置该往哪移动(正负),以及移动多少(大小)
而如何计算这个梯度的算法-反向传播算法(BP, Back Propagation)就是整个神经网络的核心,这一部分将在下一章内容中阐述
总结
本章阐述了神经网络学习的根本,就是让代价函数的值最小。而为了达到这一结果,代价函数必须得是平滑的,这样我们才可以通过每次挪动一点点来找到局部最小值。这也解释了,为什么人工神经元的激活值必须是连续的。这种按照负梯度的倍数,不停调整函数输入值的过程,就叫做梯度下降法。
扩展阅读
经典教材
- Neural Networks and Deep Learning - Michael Nielsen 的经典在线教材,本文核心参考来源
视频教程
- 3Blue1Brown 神经网络系列 - 直观可视化讲解神经网络与梯度下降
- Andrew Ng 机器学习课程 - 斯坦福经典课程,深入讲解梯度下降
延伸阅读
- 梯度下降法 - 维基百科 - 系统性了解算法历史与变体