GPT
GPT的全称是生成式预训练Transformer(Generative Pre-trained Transformer)。拆分理解:
- 生成式:表示用来生成新文本的机器人
- 预训练:表示模型经历了从大量数据中学习的过程。预字则暗示,模型能针对具体任务,通过额外训练来进行微调
- Transformer:一种特殊的神经网络,一种机器学习模型
本章节及后续章节将进一步了解Transformer内部运作的方式。基于Transformer可以构建多种不同的模型,包括语音转文本,文本转语音,生图模型等。Google最早在2017年推出了原版Transformer,专注于把一种语言的文本翻译成另外一种。而我们需要关注的,则是构建ChatGPT等工具的变种模型。这些变种模型是通过输入一段文本,甚至伴随着一些图像及音频,预测出文段接下来的内容,并将结果展示为接下来不同文本片段的概率分布。乍一看,预测下一个词与生成新文本的目标截然不同,但是有了这样的预测模型后,要让它生成更长的文本,一个简单方法是给它一个初始片段,然后从它给出的概率分布中取一个片段,追加到文本末尾,再用所有文本,包括追加的内容,进行新一轮的预测。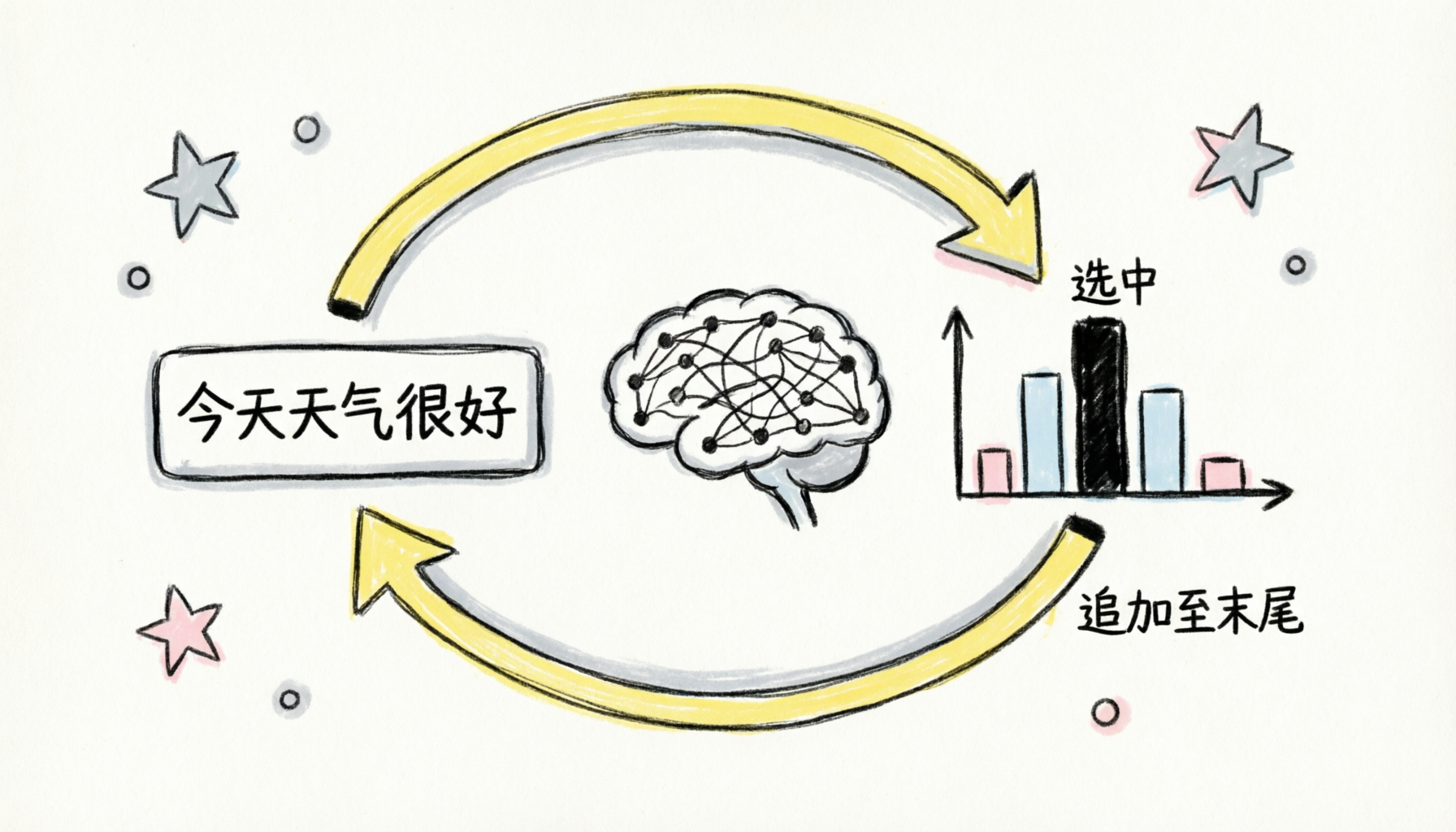
这个重复预测和抽样的过程,正是你与ChatGPT或其他大语言模型进行交互时所遇到的单词一个个蹦出来的样子
Transformer
我们先来总览一下数据是如何在Transformer中流动的。当ChatGPT等聊天机器人生成特定单词时,背后实际在做这些事情:
将输入内容切分成许多个小片段(Token),这些小片段往往是单词或者单词片段。每个Token对应一个向量,即一组数字,旨在设法编码该片段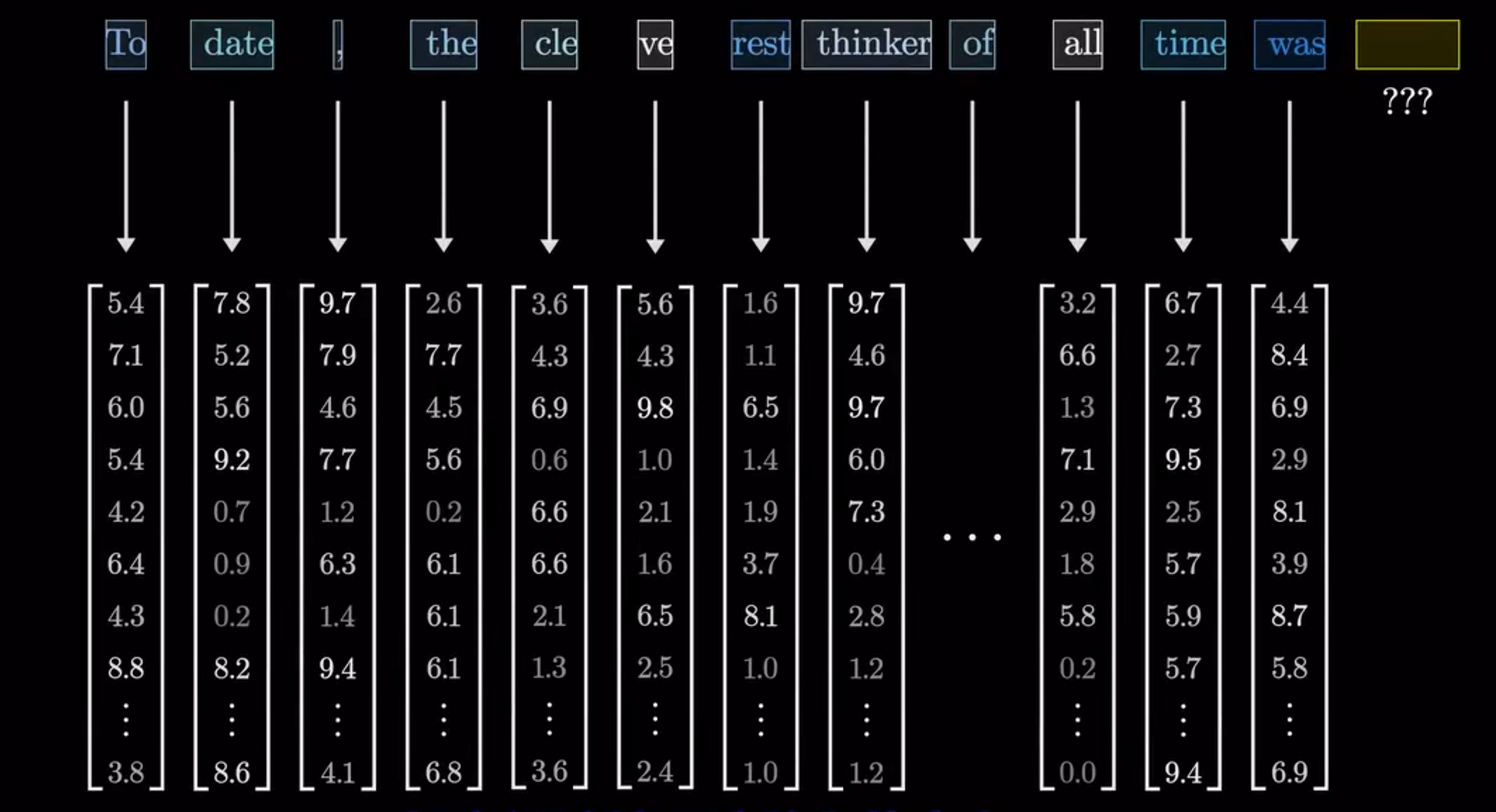
如果将向量看作高维空间中的坐标,那么意思相近的词,对应的向量往往也相近。这些向量随后经过“注意力模块”处理,使得向量之间能够相互交流。通过相互传递信息,来更新自己的值。
注意力模块的工作,就是找出上下文中哪些词会改变哪些词的含义,以及这些词应该更新为何种含义,而这里所说的含义是已经被某种形式完全编码进了向量中。
之后这些向量会经过另一层处理,取决于不同资料,有的叫做“多层感知器”(multi-layer perceptron),也有的叫做前馈层(feed-forward layer)。在前馈层,向量之间已经不再通信,而是并行经历同一处理。前馈层的处理有点抽象,可以粗浅理解为对每个向量提出一系列问题,然后根据这些问题的答案来更新向量
注意力模块和前馈层的处理,本质都是大量的矩阵乘法。我们的主要目标是弄懂,如何解读这些底层矩阵。
让我们略过中间一些归一化步骤的细节,之后就是不断的重复注意力模块和多层感知器模块,层层堆叠。最后的目标是,能将整段文字的所有关键含义以某种方式融入到序列的最后一个向量中,然后对最后一个向量进行某种操作,得出所有可能token的概率分布
这样,就像之前说的,只要能够根据给定文本,预测下一个词。就能给他喂一点初始文本,然后反复进行预测、抽样、追加这一个过程。
早在ChatGPT出现之前,GPT-3的早期演示就能根据初始文本自动补全故事和文章。要把这样的工具做成聊天机器人,最基础简单的方法就是准备一段文本,设定用户与AI助手互动的场景,即所谓的系统提示词(System Prompt)。然后将用户的初始问题或提示词,作为第一段对话,让模型预测热心的AI助手会如何回应
深度学习的基本概念和架构
深度学习是机器学习中的一种方法。而机器学习采用数据驱动,反馈到模型参数,指导模型行为。
机器学习的理念就是,不要试图在代码中明确定义如何执行一个任务,那是AI发展初期的做法,而是去构建一个具有可调参数的灵活架构,然后通过大量样本,即给定一个输入时应该输出什么,设法调节各种参数值,以模仿这种表现。
最简单的机器学习可能就是线性回归,输入和输出都是单个数字,而要做的就是找到一条最佳拟合线,这条线由两个连续参数描述,斜率和截距。线性回归的目标就是确定这些参数,以尽可能拟合数据。当然,机器学习会复杂得多,单GPT-3模型的参数就有1750亿个。但是核心问题并不是不断地增加参数的个数就能解决,有时模型要么对训练数据严重过拟合,要么根本训练不出来。
深度学习描述的一类模型,在过往的几十年中,都展现出了出色的规模化能力。他们的共同点是都使用相同的训练算法,也就是上一章讲到的反向传播算法。但是要让这种训练算法在大规模应用中有效运行,模型必须遵循某种特定的结构。只有理解了这种结构,才能更好的理解Transformer对语言处理的许多选择,否则有些选择从我们的角度来看可能显得没有道理。
首先无论你在构建何种模型,输入的格式必须为实数数组。可以是一维数列,也可以是二维数组,或者更高维的多维数组,也就是所谓的“张量”。输入数据通常被逐步转换成多个不同的层,同样每一层的结构都是实数数组。到最后一层,就是最终的输出。在深度学习中,这些模型的参数通常被称为权重。这是因为这些模型的一个关键特征就是,参数与待处理数据之间的唯一交互方式就是通过加权和。虽然模型中也有一些非线性函数,但他们并不依赖于参数
GPT-3拆解
第一步,需要将输入的文本拆分成token。模型会有一个预设的单词库,包含所有可能的词汇。这时我们将遇到第一个矩阵,称为嵌入矩阵(Embedding matrix),每个词都对应一列,这些列决定了第一步中,每个单词对应的向量
我们将嵌入矩阵记作$W_E$,就和其他矩阵一样,它的初始值随机,但将基于样本学习。早在Transformer之前,将单词转换成向量就是机器学习中的常见做法。我们通常将这种行为称为“词嵌入”
如果你要理解某个单词,它的词义显然会受到上下文语境影响,有时可能受到很远的上下文影响。因此,构建能够预测下一个单词的模型时,目标就是使其能有效结合上下文信息。而流经网络就是为了获取更多的上下文信息。这种网络一次只能处理特定数量的向量,这个数量被称为上下文长度。GPT-3的上下文长度为2048。因此GPT-3流经网络的数据就是2048列12288维数据
上下文长度限制了Transformer在预测下一个词时能结合的文本量,这就是为什么有些聊天机器人在进行长对话时,经常忘记之前的对话内容。
我们将最后一层,称为解嵌入矩阵,记作$W_U$。而最后一层需要经过softmax函数将向量乘积转换为概率
扩展阅读
官方论文
- Attention Is All You Need - Transformer原版论文,了解架构的起源
- Language Models are Few-Shot Learners (GPT-3) - GPT-3官方论文
技术博客
- The Illustrated Transformer - 图解Transformer,可视化理解架构
- The Illustrated GPT-2 - 图解GPT-2工作原理
实践教程
- Hugging Face Transformers - 主流Transformer库文档
- NanoGPT - Karpathy的简洁GPT实现,适合学习
延伸阅读
- 3Blue1Brown Neural Networks Series - 神经网络可视化系列视频