前言
提示词链(Prompt Chaining)是 Agentic Design Patterns 中的核心模式之一,它通过将复杂任务分解为多个有序的子任务,并通过一系列提示词逐步引导 AI 完成最终目标。
提示词链模式概述
提示词链(Prompt Chaining),有时也称为管道模式(Pipeline pattern),是利用大型语言模型(LLM)处理复杂任务的强大范式。这种方法不再要求LLM在单一的整体化步骤中解决复杂问题,而是采用分而治之的策略:将原本令人望而却步的问题分解为一系列更小、更易管理的子任务,每个子任务问题通过专门设计的提示词单独处理,一个提示词的输出会作为输入策略性地传递给链中的下一个提示词。
这种顺序处理技术天然地为与LLM的交互引入了模块化和清晰性。通过分解复杂任务,每个单独的步骤都变得更容易理解和调试,使整个过程更加健壮和可解释。链中的每一步都可以精心设计和优化,专注于更大问题的特定方面,从而产生更准确、更聚焦的输出。
一个步骤的输出作为下一个步骤的输入至关重要。这种信息传递建立了依赖链,其中先前操作的上下文和结果指导后续处理。
此外,提示词链不仅仅是分解问题,它还支持集成外部知识和工具(MCP和Skill)。这种能力极大地扩展了LLM的潜力,使它们不再仅作为独立模型运行,而是成为更广泛、更智能系统的组成部分。
提示词链的重要性超过了简单的问题解决。它是构建复杂AI智能体系统的基础技术。这些智能体可以利用提示词链在动态环境中自主规划、推理和行动。通过策略性地构建提示词序列,智能体可以参与需要多步推理、规划和决策的任务。这样的智能体工作流可以更紧密地模拟人类思维过程,从而实现与复杂领域和系统更自然、更有效的交互。
单一提示词的局限性: 对于多维任务,使用单一的复杂提示词往往效率低下。LLM可能难以处理多重约束和指令,导致以下问题:
- 指令忽略:部分提示内容被忽略
- 上下文偏离:模型失去对初始上下文的追踪
- 错误传播:早期错误被放大
- 上下文窗口不足:模型获取的信息不足以生成响应
- 幻觉:认知负荷增加导致生成错误信息
通过顺序分解增强可靠性:提示词链通过将复杂任务分解为聚焦的、顺序的工作流来解决这些挑战,显著提高了可靠性和控制力。
结构化输出:提示词链的可靠性高度依赖于步骤之间传递的数据完整性。如果一个提示词的输出不明确格式或格式不佳,后续提示词可能由于错误的输入而失败。为了缓解这一问题,制定结构化输出格式(如JSON或XML)至关重要。这种结构化格式确保数据是机器可读的,可以精确解析并无歧义地插入到下一个提示词中。
代码示例
实现提示词链的范围从脚本中的直接顺序工具调用,到利用专门设计用于管理控制流、状态和组件集成的框架。诸如LangChain、LangGraph、Crew AI和Google智能体开发工具包(ADK)等框架,提供了用于构建和执行这些多步过程的结构化环境。
以下代码实现了一个两步提示词链,作为数据处理管道运行。初始阶段旨在解析非结构化文本并提取特定信息。后续阶段接收此提取的输出并将其转换为结构化数据格式。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
## 为了更好的安全性,从 .env 文件加载环境变量
## from dotenv import load_dotenv
## load_dotenv()
## 确保你的 OPENAI_API_KEY 在 .env 文件中设置
## 初始化语言模型(推荐使用 ChatOpenAI)
llm = ChatOpenAI(temperature=0)
## --- 提示词 1:提取信息 ---
prompt_extract = ChatPromptTemplate.from_template(
"从以下文本中提取技术规格:\n\n{text_input}"
)
## --- 提示词 2:转换为 JSON ---
prompt_transform = ChatPromptTemplate.from_template(
"将以下规格转换为 JSON 对象,使用 'cpu'、'memory' 和 'storage' 作为键:\n\n{specifications}"
)
## --- 利用 LCEL 构建处理链 ---
## StrOutputParser() 将 LLM 的消息输出转换为简单字符串。
extraction_chain = prompt_extract | llm | StrOutputParser()
## 完整的链将提取链的输出传递到转换提示词的 'specifications' 变量中。
full_chain = (
{"specifications": extraction_chain}
| prompt_transform
| llm
| StrOutputParser()
)
## --- 运行链 ---
input_text = "新款笔记本电脑型号配备 3.5 GHz 八核处理器、16GB 内存和 1TB NVMe 固态硬盘。"
## 使用输入文本字典执行链。
final_result = full_chain.invoke({"text_input": input_text})
print("\n--- 最终 JSON 输出 ---")
print(final_result)这段Python代码演示了如何使用LangChain库处理文本。它利用两个独立的提示词:一个从输入字符串中提取技术规格,另一个将这些规格格式化为JSON对象。ChatOpenAI模型用于语言模型交互,StrOutputParser确保输出为可用的字符串格式。LangChain表达式语句(LCEL)用于优雅地将这些提示词和语言模型链接在一起。第一个链extraction_chain提取规格。然后full_chain获取提取的输出,并将其用作转换提示词的输入。提供了描述笔记本电脑的示例输入文本。使用此文本调用full_chain,通过两个步骤处理它。最后打印最终结果,即包含提取和格式化规格的JSON字符串。
上下文工程和提示工程
上下文工程是在 token生成之前系统地设计、构建和向AI模型提供完整信息环境的学科。这种方法论断言,模型输出的质量较少依赖于模型架构本身,而更多依赖于所提供的上下文的丰富性
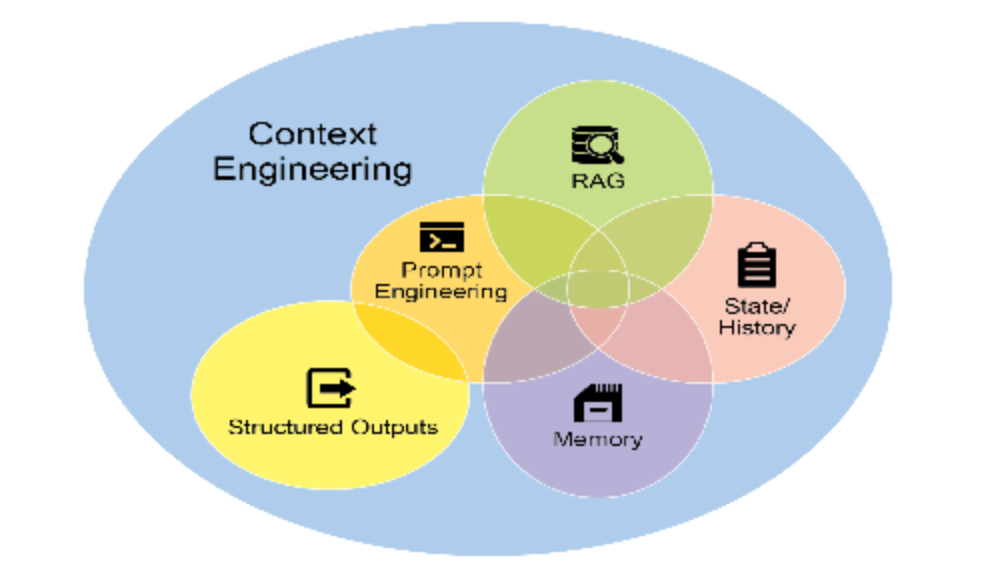
它代表着从传统提示工程的重大演进,传统提示工程主要专注于用户及时查询的措辞。上下文工程将这一范围扩展到包括多层信息,例如系统提示词,这是定义AI操作参数的基础指令集——例如:“你是一名技术作家;你的语气必须正式且精确”。上下文通过外部数据进一步丰富。这包括检索文档,其中AI主动从知识库获取信息以指导其响应,例如提取项目的技术规格。它还整合了工具输出,这是AI使用外部API获取实时数据的结果,例如查询日历以确定用户的可能性。这些显示数据与关键的隐式数据(如用户身份、交互历史和环境状态)相结合。核心原则是,即使是高级模型,在提供有限或构建不良的操作环境视图时也会表现不佳。
这种结构化方法是区分基本AI工具与更复杂、上下文感知系统的关键。它将上下文本身视为主要组件,对智能体系统知道什么、何时知道以及如何使用该信息给予关键重要性。这种实践确保模型对用户的意图、历史和当前环境有全面的理解。最终,上下文工程是将无状态聊天机器人提升为高度能干、情感感知系统的关键方法论。
扩展阅读
官方文档
- LangChain Documentation - LangChain官方文档,详细介绍提示词链的实现
- LangGraph Documentation - 构建复杂Agent工作流的官方指南
技术博客
- Prompt Engineering Guide - 提示词工程完整指南
- LLM Patterns - LLM应用设计模式合集
实践教程
- Building LLM Applications - Anthropic官方最佳实践
- Google Agent Development Kit - Google智能体开发工具包
延伸阅读
- ReAct Pattern - 推理+行动模式的经典论文
- Chain-of-Thought Prompting - 思维链提示技术